I am on a team at work that is responsible for building and maintaining a midsize but growing React application monorepo. All in all, my team is responsible for around 10 applications and 2 libraries which live alongside a handful of other applications that are maintained by other teams. When you add all of it together, there are around 16 different applications and libraries in the monorepo.
Monorepos present an interesting challenge when it comes to building and testing in CI/CD pipelines. When any change is made to the monorepo, something needs to be built and tested, but what exactly needs to be built and tested? How do we know what has changed? How do we know what the changed package depends on? How do we build those dependencies before the changed package? How do we know if the dependencies have dependencies and how do we build those in the correct order? How can we build and test any dependent applications when the dependencies were updated? How can we do all of this in parallel to save time?
All of these were questions that we had to answer when we started building our CI solution. Whenever I joined the team back in 2021, my team had solved these problems with a homegrown bash script that always built all dependencies (which was only 1 package at the time in all fairness) and then built the changed packages which were determined by parsing the git diff. This worked well enough for a while, but as the monorepo grew, it became more and more of a bottleneck. It was taking upwards of 30 minutes to build and test the monorepo when several packages were changed or whenever a dependency package was changed. This was unacceptable. We needed all of this functionality, but we needed it to be running in parallel.
Enter Nx. Nx is a tool that was created by the folks at Nrwl to solve the problems that we were facing. Nx is a CLI tool that is built on top of the Angular CLI. It provides a lot of functionality, but the most important for us was the ability to determine what packages needing to be built and in what order. Nx does this by creating a dependency graph of all of the packages in the monorepo. It then uses this graph to determine what packages need to be built and in what order. Oh, and it will do it all in parallel. That was an easy fix, right?
Unfortunately, Nx has an achilles heel. It runs each task whether building, testing, linting, etc. on a single thread. Each thread needs a core to run on. This means that if you have 10 tasks to run, you need 10 cores to run them all at the same time. If you only have 8 cores, then 2 of the tasks will have to wait until a core is available. This is a problem because the runners that our CI/CD pipeline runs on only have 2 cores, and one of them is used by the Docker image which leaves only 1 core for Nx to use bringing us back to the original problem.
Now, before you ask, yes, we checked to see if we could get more cores on the runners. For technical and prioritization reasons, we were not able to get more cores on the runners anytime soon. We had to find another way. We needed to find a way to distribute the tasks across multiple runners.
As I was researching ways to do this, I came across this article describing a way to dynamically generate a Gitlab CI/CD pipeline using a JS script that parses Nx's output. This was exactly what we needed. We could use this method to generate a pipeline that would run a job for each changed package.
That was the starting point that we needed, but we still had a key problem to solve. How do we define the order of jobs to be ran and how could we do it if there are multiple layers of dependencies?
So let's summarize where we are at this point. We have a way to know what packages are changed. We have a way to generate a pipeline that will run a job for each changed package. We have a way to run each job in parallel. What we need now is a way to define the order of the jobs.
Let's say we have 5 packages in our monorepo - A, B, C, X, and Y. Packages A, B and C are our applications and packages X and Y are our libraries. Package A depends on packages X and Y. Package B depends on package Y. Package C depends on package X. Package Y depends on package X. Package X has no dependencies.
See the visual representation below. 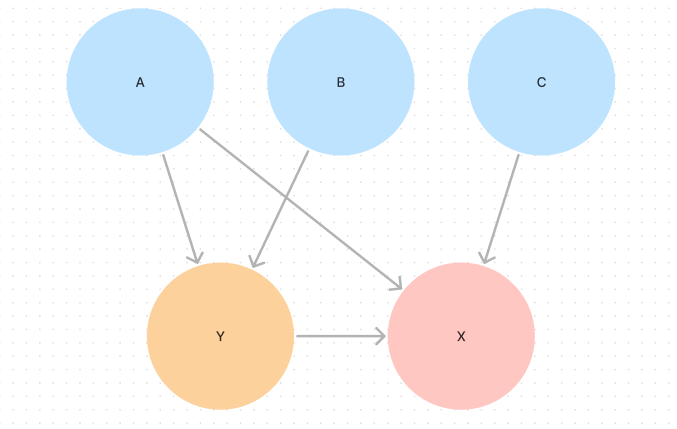
Let's spell out what dependencies and subdependencies each package has. Package A directly depends on packages X and Y. Package B directly depends on package Y and has a subdependency of package X. Package C directly depends on package X. Package Y directly depends on package X. Package X has no dependencies.
If package A gets changed, we need to build packages X, Y, and A in that order.
If package B gets changed, we need to build packages X, Y, and B in that order.
If package C gets changed, we need to build packages X and C in that order.
If package Y gets changed, we need to build packages X and Y in that order but then also build packages A and B in parallel.
If package X gets changed, we need to build package X, then build packages Y and C in parallel, and then build packages A and B in parallel.
So, how do we define this order in our pipeline? With the needs keyword in Gitlab CI/CD.
The needs keyword in Gitlab CI/CD allows you to define dependencies between jobs. If a job has a dependency, it will not run until all of its dependencies have completed successfully. This is exactly what we need. We can define the dependencies between jobs and let Gitlab CI/CD handle the rest.
We then need to make the resources of each job available to the jobs that depend on it. We can do this by using the artifacts keyword in Gitlab CI/CD.
artifacts are files that are created by a job that can be used by other jobs. This is how we will make the dist files of our dependencies available to the jobs that depend on them.
Let's see an example of how needs and artifacts work together.
build:Y:
stage: build
rules:
- if: $CI_PIPELINE_SOURCE == "parent_pipeline"
needs:
- job: build:X
artifacts: true`
script:
- cd packages/Y
- yarn build
artifacts:
paths:
- packages/Y/dist
In this example, we have a job called build:Y that depends on the job build:X. The build:X job will run first and when it completes successfully, the build:Y job will run. The build:X job will create an artifact of the dist folder of package X. This artifact will be available to the build:Y job. The build:Y job will then run the build script for package Y. When it completes successfully, the dist folder of package Y will be available as an artifact to any jobs that depend on it.
Now that we have all of the pieces, let's put it all together. First, let's start with the job that will install all of the dependencies for the entire monorepo. This job will run first and will be the only job that runs in the install stage.
install-dependencies:
stage: initialize
rules:
- if: $CI_PIPELINE_SOURCE == "merge_request_event"
script:
- yarn install
artifacts:
expire_in: 1 day
paths:
- node_modules/
- packages/**/node_modules/
Next, let's create a job that will generate the pipeline. This will run after the install-depenencies job is finished since it needs the dependencies to be installed.
generate-pipeline:
stage: initialize
rules:
- if: $CI_PIPELINE_SOURCE == "merge_request_event"
needs:
- job: install-dependencies
artifacts: true
script:
- npx nx graph --file=projectGraph.json
- node ./.cicd/generateDynamicChildPipelines.js "$(npx nx show projects --affected --base=origin/master)"
- cat dynamic-gitlab-ci.yml
artifacts:
expire_in: 1 day
paths:
- dynamic-gitlab-ci.yml
Let's dive into this a bit deeper. First, we are using the nx graph command to generate a dependency graph of all of the packages in the monorepo. We are using the --file flag to tell Nx to output the dependency graph to a file called projectGraph.json. Next, we are using the nx show projects --affected command to get a list of all of the projects in the monorepo that have changed since the origin/master branch. We are then passing this list of projects to our generateDynamicChildPipelines.js script. This script will parse the dependency graph and the list of changed projects and generate a dynamic Gitlab CI/CD pipeline. We are then using the cat command to output the generated pipeline to the console. This is important because we need to be able to see the generated pipeline in the Gitlab CI/CD logs for potentisl debugging purposes. Finally, we are using the artifacts keyword to make the generated pipeline available to the next job.
build:packages:
stage: trigger
rules:
- if: $CI_PIPELINE_SOURCE == "merge_request_event"
needs:
- generate-pipeline
trigger:
include:
- artifact: dynamic-gitlab-ci.yml
job: generate-pipeline
strategy: depend
variables:
PARENT_PIPELINE_ID: $CI_PIPELINE_ID
This job is where the magic happens. This job will run after the generate-pipeline job is finished since it needs the generated pipeline to run. This job will trigger a child pipeline for each job in the generated pipeline. The include keyword is used to include the generated pipeline as a child pipeline. The strategy keyword is used to tell Gitlab CI/CD to run each child pipeline in parallel. Finally, we are using the variables keyword to pass the CI_PIPELINE_ID of the parent pipeline to each child pipeline. This is important because we need to be able to access artifacts from the parent pipeline in the child pipelines.
Now that we have seen how the child pipelines are triggered, let's take a look at the script that generates the child pipelines.
// .cicd/generateDynamicChildPipelines.js
const { readFileSync, appendFileSync } = require('fs');
let deps;
function createDynamicGitlabFile() {
const { dependencies, changedProjects } = getChangedPackagesAndDependencies();
deps = dependencies;
if (!changedProjects.length) {
writeDynamicGitlabFile(createEmptyJob());
return;
}
const affectedProjectDependencyGroups = getAffectedProjectDependencyGroups(changedProjects);
const uniquePackagesToBeBuilt = removeDuplicatePackageEntries(affectedProjectDependencyGroups.flat());
const packageTestJobs = createBuildJobs(uniquePackagesToBeBuilt);
writeDynamicGitlabFile(packageTestJobs);
}
This is the entry point of the script. First, we are getting a list of all of the changed packages and their dependencies. Next, we are creating a list of all of the unique packages that need to be built. Finally, we are creating a list of jobs that will run the build script for each package. We are then writing the generated jobs to a file called dynamic-gitlab-ci.yml. Let's take a look at the getChangedPackagesAndDependencies, createEmptyJob, getaffectedProjectDependencyGroups, removeDuplicatePackageEntries, and createBuildJobs functions.
// .cicd/generateDynamicChildPipelines.js
function getChangedPackagesAndDependencies() {
const {
graph: { dependencies },
} = JSON.parse(readFileSync('projectGraph.json', 'utf8'));
const [stringifiedAffected] = process.argv.slice(2);
// Sometimes the stringified affected projects will not have a trailing newline so filter out empty strings in the array
const changedProjects = stringifiedAffected.split('\n').filter((project) => project !== '');
return { changedProjects, dependencies };
}
This function is responsible for getting a list of all of the changed packages and their dependencies. First, we are reading the projectGraph.json file that was generated by the nx graph command. Next, we are getting the list of changed packages from the command line arguments. Finally, we are returning the list of changed packages and the dependency graph.
// .cicd/generateDynamicChildPipelines.js
function createEmptyJob() {
// Spacing is wonky because YML files care about spacing
return `
build:empty:
stage: build
rules:
- if: $CI_PIPELINE_SOURCE == "parent_pipeline"
script:
- echo 'no apps affected'
`;
}
This function is responsible for creating an empty job that will run if no packages have changed. This is important because we need to have at least one job in the pipeline. If we don't, Gitlab CI/CD will throw an error.
// .cicd/generateDynamicChildPipelines.js
const seenPackages = [];
function getAffectedProjectDependencyGroups(packages) {
return packages.map((pkg) => {
if (seenPackages.includes(pkg)) {
return [pkg];
}
seenPackages.push(pkg);
const pkgDeps = deps[pkg].map(({ target }) => target);
return [pkg, ...getAffectedProjectDependencyGroups(pkgDeps)].flat();
});
}
This function is responsible for creating a list of lists of packages that need to be built. First, we are creating an array called seenPackages that will be used to keep track of which packages have already been added to the list. Next, we are mapping over the list of changed packages. For each package, we are checking to see if it has already been added to the list. If it has, we are returning a list with only that package. If it has not, we are adding it to the list and then getting the list of dependencies for that package. We are then recursively calling the getAffectedProjectDependencyGroups function with the list of dependencies. Finally, we are flattening the list of lists and returning it. The cool part of this function is that in theory it should be infinitely scalable! It will keep going until it has found all of the dependencies for each package no matter how many layers deep they are.
NOTE: There will be duplicates in the list of lists. I didn't care though since all duplicates will be removed later on.
// .cicd/generateDynamicChildPipelines.js
function removeDuplicatePackageEntries(packages) {
return [...new Set(packages)];
}
This function is responsible for removing duplicate packages from the list of lists.
// .cicd/generateDynamicChildPipelines.js
function createTestJobs(packages) {
return packages.map(createTestJob).join('\n');
}
function createTestJob(package) {
const dependencyNeeds = getDependencyNeedsForPackage(package);
// Spacing is wonky because YML files care about spacing
return `
build:${package}:
stage: build
rules:
- if: $CI_PIPELINE_SOURCE == "parent_pipeline"
needs:
- pipeline: $PARENT_PIPELINE_ID
job: install-dependencies${dependencyNeeds}
script:
- cd packages/${package}
- yarn build
artifacts:
paths:
- packages/${package}/dist/
expire_in: 1 day
`;
}
function getDependencyNeedsForPackage(package) {
return deps[package].map(createNeedsEntry).join('');
}
function createNeedsEntry({ target }) {
// Spacing is wonky because YML files care about spacing
return `
- job: build:${target}
artifacts: true`;
}
These functions are responsible for creating a list of jobs that will run the build script for each package. First, we are mapping over the list of packages and calling the createTestJob function for each package. Next, we are creating a job for each package. We are using the needs keyword to tell Gitlab CI/CD that each job depends on the install-dependencies job of the parent pipeline and any other jobs that the package depends on. We are then using the script keyword to run the build script for the package. Finally, we are using the artifacts keyword to make the dist folder of the package available to any jobs that depend on it. Also note the createNeedsEntry function. This function is responsible for creating the needs entries for each dependency of the package.
And that's it! That's how we were able to distribute Nx tasks across multiple Gitlab runners. Once this was implemented, we saw our pipeline times cut in half, saving 15 minutes in worst case scenarios and 3-4 in best case scenarios. I hope this helps you in your journey to build and maintain a monorepo.